Removendo o Mistério do endereçamento
SEGMENT : OFFSET
Direitos reservados©2004,2007,2009,2017 para Daniel B. Sedory
Esta página pode ser copiada gratuitamente apenas para uso pessoal !
( Não pode ser usada para qualquer outro propósito, a menos que você tenha
primeiro contatado (somente em inglês) e tenha recebido permissão de Daniel B. Sedory ! )
Sítio traduzido para a língua portuguesa por
Augusto Manzano com autorização expressa de Daniel B. Sedory
Acesse aqui a versão original em inglês.
Freqüentemente há muitos pares de "Segment:Offset" que podem ser usados para endereçar o mesmo local na memória do seu computador. Este esquema é uma forma relativa de visualizar a memória do computador em oposição a um esquema de endereçamento Linear ou Absolute. Quando um esquema de endereçamento absoluto é usado, cada local de memória tem sua própria designação exclusiva; que é uma maneira muito mais fácil para as pessoas verem as coisas. Então, por que alguém criou este estranho esquema de "Segment:Offset" para lidar com a memória do computador? Como resposta, aqui está uma breve lição sobre a CPU 8086 com uma inclinação histórica:
Segment:Offset foi introduzido em um momento em que o maior registro em uma CPU tinha apenas 16-bits, o que significava que ele poderia endereçar apenas 65.536 bytes (64 KiB[1]) de memória, diretamente. Mas todos estavam ansiosos por uma maneira de executar programas muito maiores! Em vez de criar uma CPU com tamanhos de registro maiores (como alguns fabricantes de CPU haviam feito), os designers da Intel decidiram manter os registros de 16 bits para sua nova CPU 8086 e adicionaram uma maneira diferente de acessar mais memória: Eles expandiram o conjunto de instruções, para que os programas pudessem dizer à CPU para agrupar dois registradores de 16 bits sempre que precisassem se referir a uma localização de memória Absoluta além de 64 KiB.
Se os projetistas tivessem permitido que a CPU combinasse dois registradores em um par alto e baixo de 32 bits, ela poderia ter referenciado até 4 GiB[2] de memória de forma linear! Lembre-se, no entanto, que este foi um momento em que muitos nunca sonharam que precisaríamos de um PC com mais de 640 KiB de memória para aplicativos e dados do usuário![3] Então, ao invés de lidar com quaisquer problemas que um sistema linear teria produzido com endereçamentos de 32 bits, eles criaram o esquema Segment:Offset que permite a uma CPU endereçar efetivamente cerca de 1 MiB de memória.[4]
O esquema funciona assim: O valor de qualquer registrador considerado um registrador de segmento é multiplicado por 16 (ou deslocado um byte hexadecimal para a esquerda com o acréscimo de um 0 extra ao final do número hexadecimal) e, em seguida, o valor de deslocamento do registrador é adicionado a ele. Assim, o endereço absoluto para qualquer combinação de pares de segmento e deslocamento é encontrado usando a fórmula:
|
Após trabalhar com alguns exemplos, isso se tornará muito mais claro para entender: o endereço absoluto ou linear para o par de Segment:Offset, F000:FFFD pode ser calculado facilmente em sua mente, simplesmente inserindo um zero no final do valor do Segment (que é o mesmo que multiplicar por 16) e, em seguida, adicionando o valor de Offset:
F0000 + FFFD ------ FFFFD or 1,048,573(decimal) Aqui está outro exemplo: 923F:E2FF -> 923F0 + E2FF ------ A06EF or 657,135(decimal)
Agora vamos calcular a localização da memória absoluta para o maior valor que pode ser expresso usando Segment:Offset como referência:
FFFF0
+ FFFF
-------
10FFEF ou 1,114,095 (decimal)
Na realidade, somente algum tempo depois no 8086 um valor tão grande realmente correspondeu a uma localização real da memória. Uma vez que se tornou comum os PCs terem mais de 1MiB de memória, os programadores desenvolveram maneiras de usá-lo a seu favor e esse último byte passou a fazer parte do que hoje é chamado de HMA (High Memory Area). Mas até aquele momento, se um programa tentasse usar um par Segment:Offset que excedesse um endereço absoluto de 20 bits (1 MiB), a CPU iria truncar o bit mais alto (de uma CPU 8086/8088 tem apenas 20 linhas de endereço), mapeando efetivamente qualquer valor sobre FFFFFh (1,048,575) para um endereço dentro do primeiro segmento. Assim, 10FFEFh foi mapeado para FFEFh.[5]
Uma das desvantagens em usar pares de Segment:Offset (e provavelmente o que confunde a maioria de vocês) é o fato de que um grande número desses pares referem-se às mesmas localizações exatas de memória. Por exemplo, cada par de Segment:Offset, abaixo, refere-se exatamente ao mesmo local na memória:
|
0007:7B90 0008:7B80 0009:7B70 000A:7B60 000B:7B50 000C:7B40 0047:7790 0048:7780 0049:7770 004A:7760 004B:7750 004C:7740 0077:7490 0078:7480 0079:7470 007A:7460 007B:7450 007C:7440 01FF:5C10 0200:5C00 0201:5BF0 0202:5BE0 0203:5BD0 0204:5BC0 07BB:0050 07BC:0040 07BD:0030 07BE:0020 07BF:0010 07C0:0000 |
| Os pares de Segment:Offset listados acima são apenas algumas das muitas formas de se referir à localização única da "Memória Absoluta" de: 7C00h (ou 0000:7C00). |
De fato, pode existir mais de 4.096 diferentes pares de Segment:Offset para endereçar um único byte na memória, dependendo de sua localização particular. Para endereços absolutos de 0h até FFEFh (de 0 até 65.519), o número de pares diferentes pode ser calculado da seguinte forma: Divida o endereço absoluto por 16 (o que muda todos os dígitos hexadecimais uma casa para a direita) e, em seguida, desconsidere qualquer resto fracionário e adicione 1. Isso é mesmo que dizer: Adicione 1 ao número do Segment number se o OFFSET for 000Fh (15) ou menor. Por exemplo, o byte na memória referenciado pelo par Segment:Offset 0040:0000 tem um total de 41h (ou 65) pares diferentes que podem ser usados. Para o endereço absoluto 7C00h, mencionado acima, há um total de: 7C00 / 10h --> 7C0 + 1 = 7C1 (ou 1.985) maneiras relativas de endereçar este mesmo local de memória usando o par Segment:Offset. Para os endereços absolutos de FFF0h (65.520) até FFFFFh (1.048.575), sempre haverá 4.096 pares Segment:Offset que podem ser usados para se referir a esses endereços! Isso é um pouco mais de 88% da memória que pode ser acessada usando Segment:Offsets. Os últimos 65.520 bytes que podem ser acessados por este método são chamados coletivamente de High Memory Area (HMA). Para cada 16 bytes a mais no HMA papontado há um par de Segment:Offset disponível para fazer referência a esse parágrafo.
Devido ao grande número de pares possíveis de Segment:Offset para cada endereço a maioria dos programadores concordou em usar o mesmo método de normalização (sconsulte a nota abaixo em Notação Normalizada) ao escrever sobre um local específico na memória.
Observe as ilustrações gráficas a seguir para ajudá-lo a imaginar os limites entre as várias áreas da Memória:
As ilustrações a seguir devem ajudar os estudantes a visualizarem o layout artificial dos limites dos segmentos existentes na memória de um sistema.
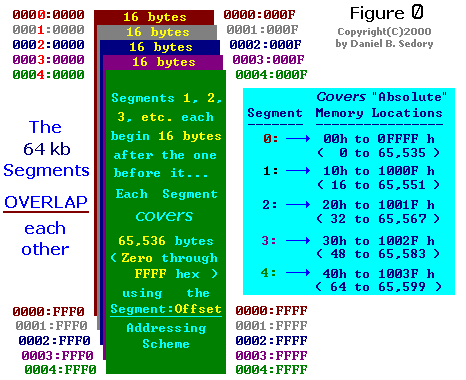
"SEGMENTS" ou segmentos são mais como uma construção mental ou forma de visualizar a memória de um computador do que estar, de fato, intimamente ligado ao próprio hardware físico, trata-se de uma abstração. Na Figura 0, busca-se mostrar como cada segmento de 65.536 bytes se sobrepõem na maior parte do segmento anterior. Como você pode ver cada segmento inicia-se apenas 16 bytes (ou um parágrafo) após o anterior. Na terminologia do computador, um parágrafo é usado para se referir a 16 bytes consecutivos de memória. Para cada 16 bytes a mais na memória que apontamos o número de segmentos sobrepostos aumentará em um até chegar ao final do primeiro segmento. Nesse ponto, cada parágrafo sucessivo da Memória (até 1 MiB) tem um número constante de 4.096 segmentos sobrepostos! A Figura 0 também mostra o valor do Segment:Offset para cada um dos quatro cantos dos primeiros cinco segmentos .
Na Figura 1 (veja abaixo) o foco está apenas no início dos Segmentos 1, 2, 3 e assim por diante ao invés de todo o segmento. Observe como os primeiros 16 bytes de memória aparecem na Figura. Há apenas um segmento lá: nenhum outro segmento se sobrepõe a esses bytes. Portanto, o par de Segment:Offset para cada um dos primeiros 16 bytes na memória são realmente únicos! Só há uma maneira de referir-se a eles: com o valor de segmento 0000: e um dos 16 deslocamentos de 0000h a 000Fh. Os próximos 16 bytes na memória (10h a 1Fh) terão cada um aproximadamente dois pares diferentes de Segment:Offset que podem ser usados para resolvê-los. Para cada um dos primeiros cinco segmentos o número exato de pares de Segment:Offset equivalentes para o último byte no parágrafo são mostrados nas caixas coloridas sinalizadas em (azul claro).
(Observações sobre a parte da Figura 1 sob a linha AZUL, consulte o texto abaixo.)
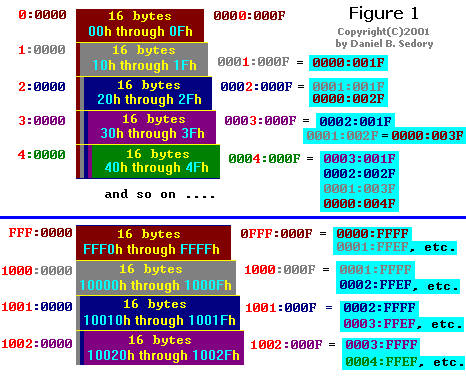
A segunda parte da Figura 1 mostra o que acontece na transição de um parágrafo de memória que ainda está dentro do limite do primeiro segmento de 64kb (endereços absolutos de FFF0h até FFFFh) para aqueles parágrafos que estão além de seu limite (10000h e posterior). Observe que o primeiro parágrafo do segmento 0FFF: (que é o mesmo que os últimos 16 bytes no segmento 0000:) é o primeiro parágrafo na memória a ter um total de 4.096 pares diferentes de Segment:Offset que podem ser usados para referenciar seus bytes.
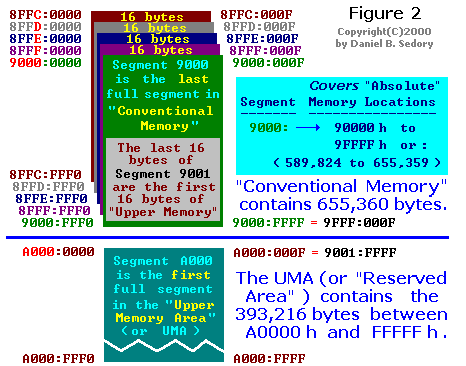
A Figura 2 apresenta o Segment 9000: é o último segmento inteiro de 64kb dentro dos limites do que é chamado de "Memória Convencional" (os primeiros 640kb ou 655.360 bytes). O primeiro parágrafo do Segmento A000: é o início da Área de Memória Alta (UMA - Upper Memory Area). A UMA contém um total de 384kb ou 393.216 bytes. Segmento F000: é o último segmento inteiro que está dentro dos limites da UMA.
640 KiB + 384 KiB = 1024 KiB (ou 1.048.576 bytes) = 1 Mebibyte.
(Há muito tempo a UMA era chamada de 'Área Reservada'.
Outra maneira de olhar para o primeiro 1MiB de memória (e esperançosamente algo que ajudará aqueles que ainda possam estar confusos) é o fato de que cada um desses 1.048.576 bytes podem ser acessados usando apenas um dos seguintes 16 segmentos de referência (nenhum dos quais se sobrepõem a qualquer um dos outros): 0000:, 1000:, 2000:, ... 9000: e A000: até F000: mais uma das 65.536 compensações. Embora fosse realmente bom se pudéssemos sempre nos referir a um byte específico na memória usando apenas esses 16 segmentos, isso seria um grande desperdício de recursos de memória: Quando chega a hora de um sistema operacional como o Windows atribuir 64kb de memória livre a um aplicativo como o DEBUG, não é simplesmente uma questão de conveniência usar a primeira referência de segmento de 16 bytes de memória contínua que se pode encontrar. Mover-se para o próximo segmento de 1000h deixaria ainda mais buracos não utilizados na memória do que já existem! (Aqui está, no entanto, uma convenção acordada chamada Normalized Addressing (Endereço Normalizado) que tem sido muito útil.)
A Figura 3 mostra o final da UMA e o início do último segmento (Segment FFFF:) no modelo Segment:Offset. Quando o 8086 foi criado, não havia nem 640kb de memória na maioria dos PCs. E, como você deve se lembrar da lição de história acima, os endereços nesta parte do modelo Segment:Offset foram mapeados primeiro para os bytes no Segment 0000. Mais tarde, a memória acima de 1 MiB que ainda podia ser acessada usando pares de deslocamento Segment:Offset tornou-se conhecida como The High Memory Area (HMA).

A High Memory Area (HMA) contém apenas um parágrafo curto de 64 kb (ou apenas 65.520 bytes). Segment FFFF: é o único segmento que pode atingir os últimos 16 bytes do HMA. Aqui está um extenso arquivo de texto da Tabela dos pares de HMA Segment:Offset que mostra como o número de pares diminui para apenas um nos últimos 16 bytes do HMA.

Uma vez que existem tantas maneiras diferentes que um único byte na memória pode ser referenciado usando oares de Segment:Offset, a maioria dos programadores concordou em usar a mesma convenção de normalizar todos esses pares em valores que sempre serão únicos. Esses pares exclusivos são chamados de Endreços Normalizados ou Ponteiros.
Limitando o deslocamento apenas aos valores hexadecimais de 0h até Fh (16 dígitos hexadecimais); ou um único parágrafo e definindo o valor do segmento de acordo, temos uma maneira única de fazer referência a todos os pares de Segment:Offset de memória alocados. Para Para converter de forma arbitrária um par de Segment:Offset em um endereço normalizado ou na forma de ponteiro é um processo de duas etapas muito fácil de ser realizado por um programador Assembly:
Por exemplo, para normalizar 1000:1B0F, as etapas são:
1000:1B0F ![]() 11B0Fh
11B0Fh ![]() 11B0:F (ou 11B0:000F)
11B0:F (ou 11B0:000F)
Uma vez que a forma normalizada sempre terá três bytes zero à esquerda em seu Offset, os programadores geralmente a escrevem com apenas o dígito efetivo, conforme mostrado aqui: 11B0:F (quando você vê um endereço como este, é quase certo de que o autor usou esta forma de notação normalizada).
A notação normalizada para o primeiro byte do código de todos os PC BIOS foram colocados em um disquete na faixa de inicialização (bootstrap): 07C0:0 (ou seja, 07C0:0000). Um grande problema para alguns fabricantes de PCs ocorreu quando gravaram suas BIOS presumindo que não haveria nada de errado saltar o código para aquela faixa de inicialização (bootstrap) particularmente naquele par de Segment:Offset, já que é o mesmo local de memória indicado como 0000:7C00.
De alguma forma, eles não levaram em consideração o fato de que o padrão usado pelos outros fabricantes definiu os valores do SEGMENTO para ZERO. Portanto, um programador de código para bootstrap pode assumir que todos os valores do Segment (código, dados, etc.) são zero e que precisam lidar apenas com os valores do Offset nesse segmento. Então chegou o clone do chip BIOS que definia o segmento de código para 07C0 (usando uma instrução: JMP 07C0:000) e, de repente, ocorreu um grande problema para a maioria do código de bootstrap dos Sistemas Operacionais (incluindo Microsoft® e IBM®) para conseguirem inicializar esses computadores! É por isso que alguns códigos de bootstrap, como o do GRUB Boot Manager (Gerenciador de Boot GRUB - em inglês) adicionam instruções extras para garantir que os segmentos dos registros sejam configurados corretamente! Um dos autores do GRUB comenta que seu código de "Long Jump" era necessário "porque algumas BIOS alternativas (falsas) saltam para o endereço 07C0:0000 ao invés de saltarem para o endereço 0000:7C00".
Notas de rodapé
1[Retornar ao texto ] KiB é a abreviatura de kibibyte (uma contração de kilo binary byte), ou seja, kilobyte binário. Isto é igual a 2 elevado a 10a. potência (2^10), ou seja, 1.024 bytes. Da mesma forma, MiB é um mebibyte (megabyte binário) que é o mesmo que 2 elevado a 20a. potência (2^20), ou seja, 1.048.576 bytes, e GiB é um gibibyte (gigabyte binário) que é o mesmo que 2 elevado a 30a. potência (2^30), ou seja, 1.073.741.824 bytes. Neste documento, a referência as memórias dos primeiros IBM PCs (e nas CPUS Intel 8086 e 80286), são por vezes referenciadas como kibibytes a partir do uso da abreviatura "kb" em vez de KiB. (Está demorando muito para que "kibi-", "mebi-" e "gibi-" sejam reconhecidos pelos departamentos de tecnologia e vendas de computadores como a maneira mais adequada de se referir à memória, mesmo que tenham estado em organizações de padrões oficiais por muitos anos. Veja, por exemplo, ![]() NIST: Prefixos para múltiplos binários, e
NIST: Prefixos para múltiplos binários, e ![]() Adoção pelo IEC e NIST.)
Adoção pelo IEC e NIST.)
64 KiB é igual a 2 elevado a 16a. potência, ou seja, [ (2^16) = (2^10) x (2^6) = (1024) x (64) = 65.536 ] bytes, e cada um dos registros de dois bytes (ou 16 bits) em uma CPU 8086 pode conter um valor máximo de: 1111 1111 1111 1111 em binário ou FFFFh (hexadecimal). Em decimal, isso equivale a: [(15 x 16^3) + (15 x 16^2) + (15 x 16^1) + 15] = [(15 x 4096) + (15 x 256) + (15 x 16) + 15] = 61.440 + 3.840 + 240 + 15 = 65.535. No entanto, como a memória sempre começa com zero (0) acomo seu primeiro local, isso nos dá 65.535 + 1 = 65.536 (ou, 16^4) locais de memória. 65.536 dividido por 1.024 por KiB = 64 KiB de memória. Para obter maiores informações sobre o uso de números hexadecimal em computadores, consulte: What Is "Hexadecimal"? (O que é "Hexadecimal" - em inglês.
2[Retornar ao texto ] Isso equivale a 4 gibibytes (consulte a nota de rodapé #1) ou 4 vezes (2^30) = 4.294.967.296 bytes.
3[Retornar ao texto ] Muitas vezes ouvimos que Bill Gates disse algo no sentido de que: ‘640K de memória deveria ser suficiente para qualquer pessoa.’ Embora muitos de nós não acreditem mais que ele tenha dito essas palavras exatas (e ele finalmente fez algumas negações públicas sobre isso), ele o fez, indiretamente no entanto, durante uma entrevista em vídeo com David Allison em 1993 para o Museu Nacional de História Americana, Smithsonian Institution, ao dizer: "Eu dispus a memória de forma que os 640K inferiores fossem RAM de uso geral e os 384 superiores estivessem reservados para vídeo e ROM e coisas assim. É por isso que falam do limite de 640K. Na verdade, é um limite, não do software, de qualquer maneira, forma ou circunstância, mas é o limite do microprocessador. Essa coisa gera endereços de 20 bits que só podem endereçar um megabyte de memória. E, portanto, todos os aplicativos estão vinculados a esse limite. Isso era dez vezes o que tínhamos antes. Mas, para minha surpresa, conseguimos esgotar essa base de endereços em cinco ou seis anos e as pessoas começaram a reclamar." (de ![]() uma transcrição da entrevista, na seção "Microsoft and the Mouse" ). Para mais informações, veja:
uma transcrição da entrevista, na seção "Microsoft and the Mouse" ). Para mais informações, veja: ![]() Did Bill Gates say the 640k line? (somente em inglês) e talvez de mais interesse para outros, aqui estão algumas
Did Bill Gates say the 640k line? (somente em inglês) e talvez de mais interesse para outros, aqui estão algumas ![]() citações verificáveis do Sr. Gates. (em inglês)
citações verificáveis do Sr. Gates. (em inglês)
4[Retornar ao texto ] 1 MiB de memória é 1.048.576 bytes (2^20 bytes), mas o modelo de endereçamento Segment:Offset só permite acessar até 10FFEFh, mais um byte de memória, ou seja, 1.114.096 bytes. Teremos mais a dizer sobre isso e sobre a HMA (High Memory Area) em breve.
5[Retornar ao texto ] Como dito acima, até que um IBM PC (ou clone) realmente tivesse mais de 1MiB de memória, era conveniente para os primeiros PCs da IBM voltarem efetivamente para o início da memória sempre que os programas tentassem acessar um endereço além do limite de FFFFFh bytes.
[Desculpe, mas essa NOTA DE RODAPÉ AINDA ESTÁ EM CONSTRUÇÃO! Em breve constará alguns links sobre o teclado do IBM PC AT e a infame linha A20!]
Última revisão: 15 DE OUT. DE 2007 (15.10.2007).
Você pode escrever para im usando o: formulário de resposta online. (Abre em uma nova janela.)
Um guia para o DEBUG ![]() Página: The Starman's Realm Assembly (somente em inglês)
Página: The Starman's Realm Assembly (somente em inglês)